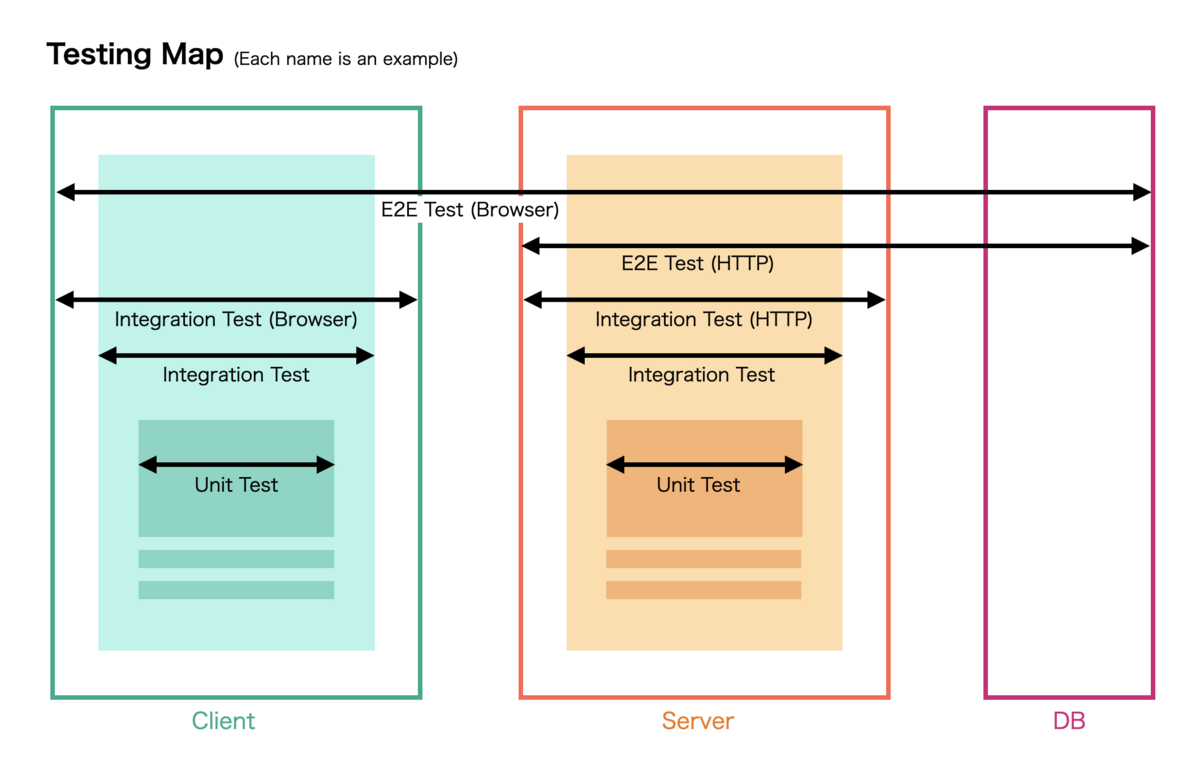
現職はスタートアップには珍しく、しっかりした QA 組織がある。日々一緒に仕事をしていて色々と発見があるので、今思うことをメモしておく。
前提として、自分は今までちゃんとした QA の人と仕事をしたことがなかった。前職はアルバイトの人に QA 相当の仕事をやってもらっていたが別に専門性があるわけではなかった。前前職には QA 組織が存在していたが、自分は技術基盤的な組織に所属していてプロダクトを作っていたわけではなかったので、関わりは全くなかった。 そうなると、そういう職種・組織が存在するということを本で読んで知ってはいたが実際どのように連携して仕事をしているのか分からない。そういう人々と関わってみたいというのが転職動機の一つでもある(ちなみに QA と同様に PdM という職種とも関わりがなかったので興味があった)。 そして9ヶ月ほど経った今になってみると「よく今まで QA なしで開発してたな」と思う。
(ところで QA ってロールを指したりプロセスを指したりでややこしいが、この記事ではロールを指している)
継続的なテスト活動
いま一緒に仕事をさせてもらっている QA は出来上がった成果物に対してテストを実施するだけでなく、企画段階から関わって仕様の明確化を手伝い、設計ドキュメントを読んで細かい仕様を質問し、テスト計画書を開発者にレビューしてもらい、そして最後にテストを実施しながら逐次フィードバックするという一連の活動をしている。このように、なるべく前工程から活動を開始することを「シフトレフト」と呼ぶようだ(恥ずかしながらこの言葉を知ったのは最近のこと)。また、テスト設計・実施だけではなくプロセス全体に関わって品質向上に貢献することを「テスト活動」と界隈では呼んでいるようだ。
テスト技法
QA がスプレッドシートにテスト項目をずらっと並べてチェックしているのを眺めていたのだが、あれは「ディシジョンテーブル(DT)」と呼ばれる歴とした技法であることを後から知った。同じエンジニアなのにテストの話をする時に今まで全然そういうワードが出てきたことがなかったなと思った。面白そうだったので、有名そうな「はじめて学ぶソフトウェアのテスト技法」を読んだ後、おすすめで出てきた「ソフトウェアテスト技法練習帳 ~知識を経験に変える40問~」を一通り解いてみた。結構気づきが多くてユニットテストや E2E テストにも応用できそう。
品質保証という観点
E2E テストは QA と開発者が同時に関わっているのだが、テストケースの見方が大分違うなという感想を得た。一言で言うと、我々開発者が適当すぎた(笑)。開発者はユニットテストについて語る時「不安なところにテストを書いて自信をつけよう」などと言うが、「不安とか自信とかなんなの」感は正直ある。ユニットテストの延長で E2E テストも「まーこんなもんだろ」みたいに感覚で書くので、多分 QA としては困惑していたと思う。結局「そのテストでどこまで品質を保証できていますか?」に答えるためには、テストケースも整然と管理されている必要がある。
コミュニティ
QA 界隈にも WACATE とか JaSST のようなイベントが頻繁あり、コミュニティが形成されているようだ。ホント全然知らなかった。観測範囲では、個別の技法を突き詰める話よりは QA が組織にどう関わるかみたいな話が多い印象。まあ重要だからそうなるの分かる。
いま考えていること
そもそもなぜ今 QA 活動に興味があるかというと、最近設計ドキュメントの粗を QA に指摘されまくって凹んだからである。「それちゃんと考えればケースが漏れてること気づいただろう」と。つまり QA がテスト設計を始める前に開発者が設計段階でミスに気づければ、その分だけ戻りが少なくなりシフトレフトに貢献できるわけ。でも QA が旗を振って開発者にそういう活動をしてもらうようにお願いするのってかなり難しい気がするので、じゃあもう自分が開発者として直接協力するのが一番早いでしょうと。痒いところにも手が届くので。 そして、前回の反省からの TRY として直近の機能では設計時に PdM・デザイナーと仕様をとことん議論してみた。単に意識を変えただけだが、おかげで今度は QA に質問攻めにあって泣きながら書き直すことは無さそうだ(多分)。